By Adrien Payong and Shaoni Mukherjee

Introduction
Scaled‑dot‑product attention (SDPA) dominates large‑language models’ (LLMs’) inference time and energy budget: almost all operator executions occur within a single primitive. Attention takes queries (Q) and multiplies them with keys (K). It then normalises the result through a softmax operation before multiplying by values (V) to produce the output. It’s memory‑bound: reading Q/K/V multiple times from high‑bandwidth memory, then writing out intermediate tiles repeatedly.
FlashAttention families reduce this bottleneck by keeping more data on the chip for longer by leveraging GPU streaming multiprocessors (SMs). First open-sourced in 2022, FlashAttention rearchitected the attention routine to compute softmax on the fly. Only a few rows of Q × K are stored on the chip at any given time.
This article serves as a practitioner-oriented deep dive into FlashAttention 4 (FA4). We’ll summarise what’s changed since previous versions and provide some guidance on adoption/benchmarking. Our goal is to equip LLM infrastructure engineers, kernel engineers, and ML platform teams with enough information to know when – and if – FA4 should be used in their stack.
Key Takeaways
- A4 is designed as a Blackwell-first attention kernel, aimed for deployment on SM100 GPUs. It features a warp-specialized 5-stage pipeline allowing for increased overlap and on-chip reuse compared to prior generations of FlashAttention.
- Efficiency is improved in softmax via two main techniques: executing software exp2() on CUDA cores themselves to reduce contention on SFUs, and adaptive online rescaling to avoid unnecessary rescale computations while preserving stability.
- There are still some missing features: FA4 is forward-first and currently lacks implementations for the backward pass, varlen, and GQA/MQA, which limits its use for training and some model architectures.
- Adopt FA4 pragmatically: use it first for Blackwell inference, gate it behind benchmarking + correctness checks + fallbacks, and keep FA3 (Hopper) / FA2 (Ampere/Ada) as the stable defaults for broad production needs.
Why attention kernels still dominate LLM cost
Despite the high FLOPS provided by GPUs, transformer models are often memory bandwidth bound due to attention having to load Q, K, and V from global memory multiple times. In order to compute attention output for every query token, each one must dot‑product with up to thousands of key tokens, normalise and rescale this result, and finally fetch values. Simple implementations compute the entire Q×K matrix and store it in memory. This exceeds the size of on-chip memory quickly, leading to performance hampered by off‑chip reads.
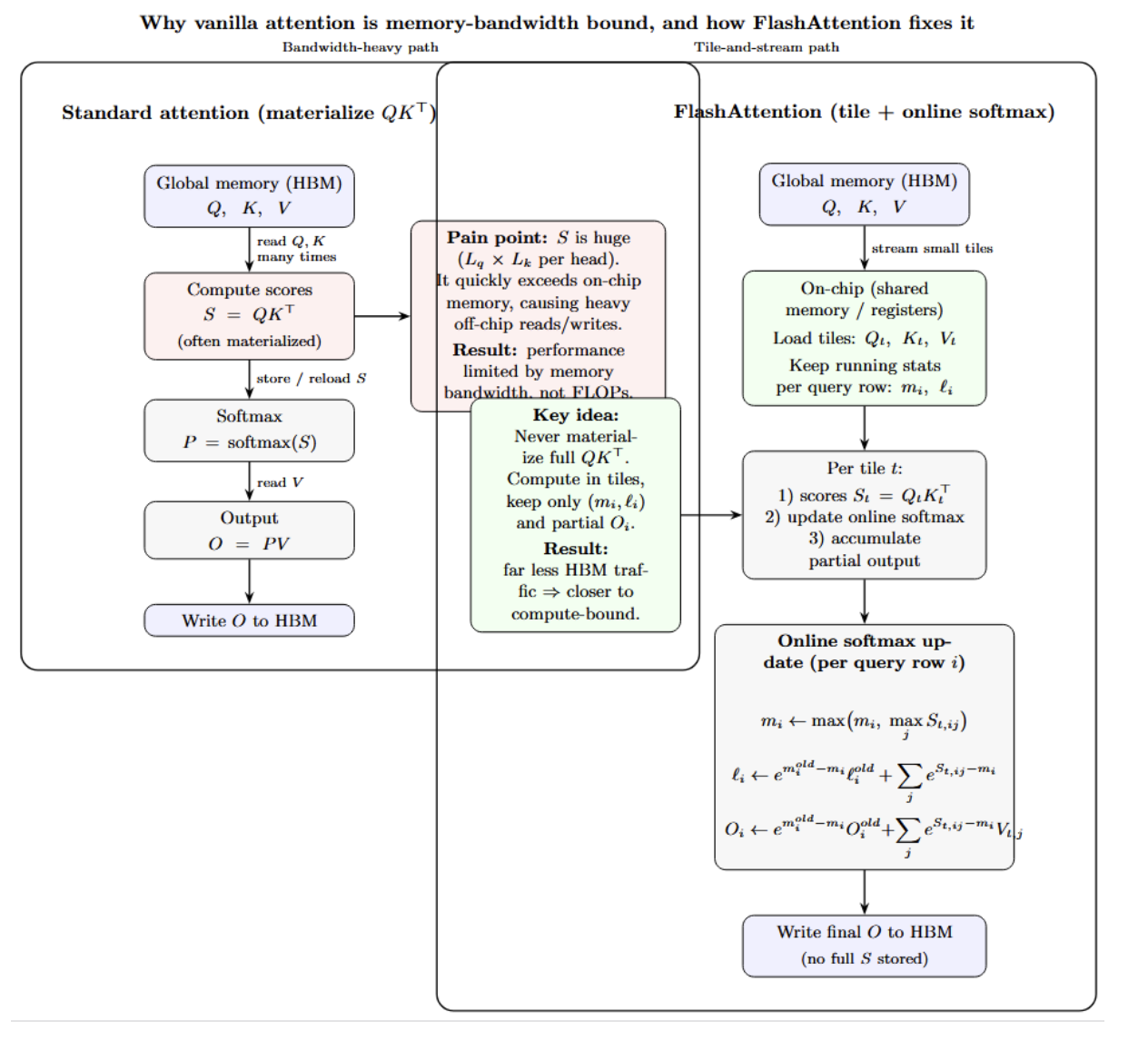
FlashAttention mitigates this problem by tiling the attention matrix. Instead of materializing Q×K, it streams small tiles of Q and K into shared memory, computes softmax over the tile, and retains only the running maximum and sum for each query row. This significantly reduces memory traffic, leading to the kernel becoming compute-bound.
FlashAttention Evolution at a Glance
It’s useful to understand how FlashAttention has evolved over time. Each version leveraged new hardware features to improve speed or efficiency. FA4 is specifically optimized for Blackwell-generation GPUs. Here’s a table of each FlashAttention version with the main improvements they brought, and their performance impact:
| Version (Year) | Target GPU Architecture | Key Innovations | Performance Highlights |
|---|---|---|---|
| FlashAttention (v1) – 2022 | Ampere (NVIDIA A100) and earlier | IO-aware exact attention (tiling + on-chip buffering) to reduce off-chip memory traffic. | 2–4× faster than baseline PyTorch attention; up to 10–20× memory savings vs naïve implementations. |
| FlashAttention-2 – 2023 | Ampere (A100), Ada (RTX 30/40) | Better parallelism & work partitioning (higher occupancy), improved warp scheduling. Multi-/grouped-query head support (MQA/GQA). | Roughly ~2× faster than v1; reaches ~50–73% of A100 theoretical FLOPs (~225 TFLOPs/s). |
| FlashAttention-3 – 2024 | Hopper (H100 / H800) | Exploits asynchronous compute & data movement (Tensor Memory Accelerator, warp specialization). Interleaved GEMM/softmax pipelines. FP8 low-precision support with improved numerical behavior. | 1.5–2× faster vs v2 on H100; ~740 TFLOPs/s FP16 (~75% utilization) and up to ~1.2 PFLOPs/s in FP8. |
| FlashAttention-4 – 2025 | Blackwell (e.g., B200, SM 10.x) | Further pipeline specialization for Blackwell concurrency. Software approximations (exp) and optimized online softmax. Kernel architecture tuned for Blackwell (via CUDA/CUTLASS/DSL). | ~20–22% faster than cuDNN attention on Blackwell in benchmarks; reported performance improvements. |
What’s New in FlashAttention 4
FlashAttention 4 continues the tiled compute paradigm established by prior FlashAttention releases: Q/K/V tensors are processed tile by tile (block by block) to maximize on-chip data locality and minimize traffic to global memory. Individual kernel instances (called a cooperative thread array, or CTA) work together to compute one or more output tiles by streaming corresponding tiles of Q, K, and V from global memory, then projecting them to the final attention outputs.
FA4’s internals consist of a highly-pipelined schedule that overlaps several stages of the attention computation to improve latency hiding and maximize GPU resource utilization. In contrast to FlashAttention 3, which has an essentially 2-stage load/compute overlap, FA4 breaks up computation into several sets of concurrent stages, with different parts of the pipeline handled by separate warp groups. These warp groups each specialize in a single responsibility during a tile’s “life cycle” through the attention function.
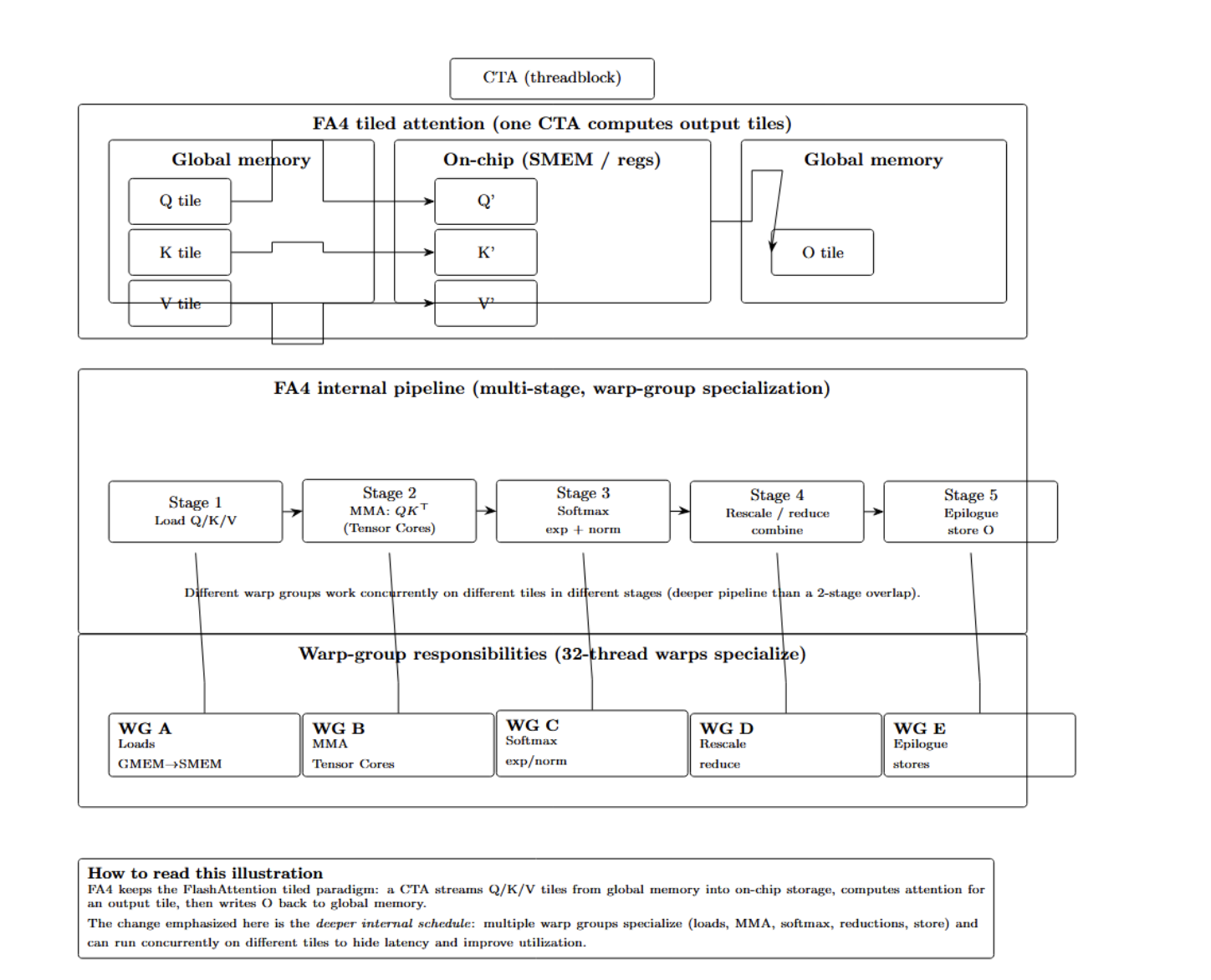
This warp specialization model assigns 32-thread warps to specific tasks, such as:
- Data movement (loads): fetching query, key, and value tiles from global memory into faster on-chip storage.
- Compute stages: Performing partial attention scores using matrix multiply-accumulate hardware with tensor cores.
- Softmax and normalization logic: Exponentials + normalization operations for attention softmax weights.
- Rescaling and reduction logic: applying numerical adjustments or combining partial results before accumulation.
- Epilogue/store operations: writing completed tiles of the output tensor back to global memory.
The intuition behind the base execution model is to maintain asynchronous pipelines for each warp group, such that the GPU warp scheduler can quickly switch between warp groups as source operands become available.
Software Exponentials via CUDA Cores
One particularly eye-catching new trick in FA4 is how it computes the exponential function used in softmax. Normally, kernels take advantage of dedicated SFUs on the GPU to perform expensive math operations like exp(). However, because there are relatively few SFUs per SM, they can easily become a bottleneck in the queue.
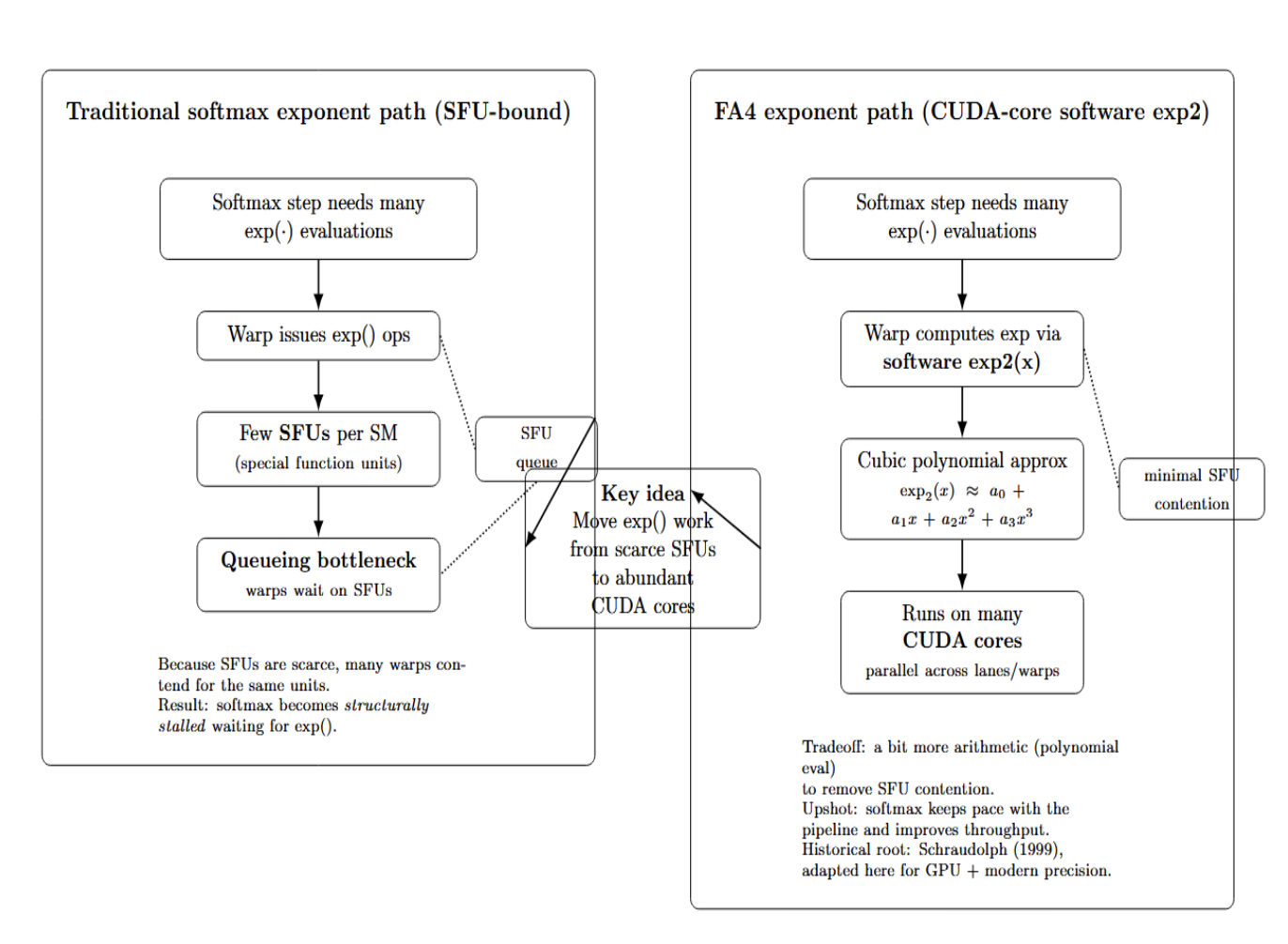
FA4 sidesteps this limitation by having normal CUDA cores perform approximate exponentials in software. Specifically, FA4 contains a custom implementation of an exp2(x) polynomial approximation with hardware precision. FA4 simulates doing the exponent calculation using a cubic polynomial, which can then be executed in parallel across many CUDA cores instead of being concentrated on a few SFUs.
The upshot: no more waiting around on SFUs to do softmax. By handling exp() on regular-purpose cores, FA4 allows the warp computing softmax to better keep pace with the pipeline.
Smarter Online Softmax Rescaling (New in FA4)
Another innovation in FA4 relates to how softmax accumulation maintains numerical stability. Like all FlashAttention versions do “online” softmax – accumulate partial max() values and sums as they stream through the sequence (to prevent overflow). Prior versions constantly updated the running scale factor (usually the max logit so far). They would rescale constantly – anytime they saw a new maximum value, they would rescale to preserve the stability of the softmax. FA4 introduces an adaptive rescaling policy. It only rescales if the new max you see is significantly bigger than the old one. This reportedly reduces the frequency of rescale operations by a factor of 10. Let’s consider the following diagram:
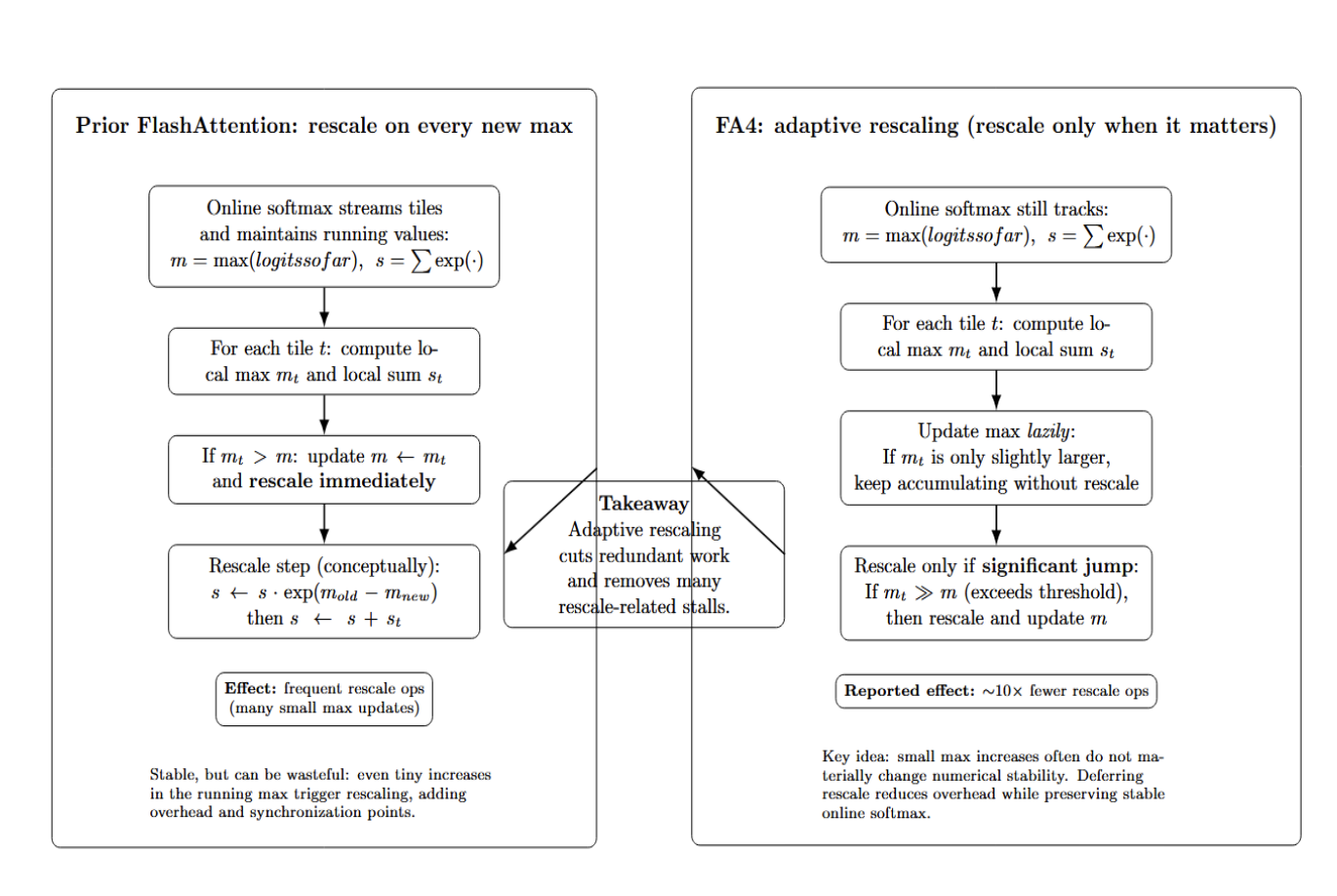
The diagram compares two versions of rescaling used in FlashAttention, enabling stable and memory-efficient computation of attention. The original strategy rescales the output of each block if the maximum value appears, ensuring small sums stay accurate by normalizing contributions step-by-step. With adaptive rescaling, we track local and global maxima, rescaling only when the jumps occur or blocks grow larger. This reduces overhead while still preventing overflow and allowing for numerically stable summation of small-value terms.
Compatibility and current status
This table provides an overview of FlashAttention 4 (FA4)'s expected and “what works today” compatibility across the stack:
| Aspect | Current Status (What Works Today) | Notes / Source |
|---|---|---|
| Hardware Target | FA4 kernels are designed for Blackwell (SM10.x / B200) GPUs | FA4 is optimized for Blackwell-generation GPUs. FA3 and prior versions support older architectures; Blackwell support is being added. (Modal) |
| Blackwell Support in Official Releases | Work in progress | Blackwell support is not yet merged into released versions; users are tracking support for the sm_120 architecture. |
| Forward Pass (FA4) | Functional / Available | The FA4 forward attention kernel has been committed and can run on Blackwell with appropriate builds. |
| Backward Pass (FA4) | Incomplete / Limited | The backward pass for Blackwell is missing key features like varlen & GQA support. |
| Variable-Length Sequence Support | Not fully supported (in backward) | Reported missing in the backward implementation; under development. |
| GQA / Grouped-Query Attention | Not yet supported (in backward) | Backward pass lacks support for grouped-query attention and similar variants. |
| Framework Integration | Not supported yet | vLLM currently recognizes only FA2 or FA3 and throws an error for FA4. (vLLM Forums) |
| Framework Integration (PyTorch SDPA) | Not yet included in stable releases | PyTorch’s scaled dot-product attention backends (SDPA) have not yet shipped FA4 support. |
| CUDA Toolkit / Driver Requirements | CUDA 12.8+ is commonly used for Blackwell builds | Blackwell/SM10 builds are typically compiled with recent CUDA toolkits (>=12.8), though specific requirements evolve with development. |
FA4’s forward pass is already widely available (committed) to the public source tree. There are open posts in projects like Lab’s FlashAttention repo where users are requesting full support for backward pass/varlen/group/GQA. This implies it is still an open public issue.
Variable-length sequence support (efficient batching of sequences with different lengths without padding) and GQA (Grouped-Query Attention) are not yet supported in the backward pass. GQA is an attention trick where multiple attention heads use the same key/value projections (sometimes used in LLMs to reduce memory usage). Previous versions of FlashAttention did support MQA/GQA style configurations. However, FA4’s main forward kernel will likely assume the same number of heads is used for each query. So it probably doesn’t support grouped heads correctly yet. Models with grouped-query attention (like some variants of Llama2) will not be supported by FA4 until this is implemented.
Ecosystem integration: FA4 is not yet adopted by many higher-level frameworks/layers because it is new. One example is the vLLM serving engine (highly optimized for LLM inference), which currently does not have FA4 support – only FlashAttention 2 and 3 are supported. Selecting FA4 in vLLM will result in an “unsupported version” error because their version selector currently only enables you to choose between versions 2 or 3.
How to Adopt FlashAttention – Decision Guide
Use this table to determine which version of FlashAttention is optimal for your needs.
| You are on Ampere/Ada (A100, RTX 30/40, etc.) | Use FlashAttention-2 (FA2) | FA4 is Blackwell-only (SM10.0) and will not run/compile on SM8.x. FA2 is the best-supported path on Ampere/Ada and is widely integrated in modern stacks. |
|---|---|---|
| You are on Hopper (H100/H200) | Use FlashAttention-3 (FA3) | FA3 was designed for Hopper and typically delivers strong gains (often cited 1.5–2× vs FA2) with mature feature coverage (backward, varlen, GQA/MQA support in common implementations). FA4 is not intended for Hopper. |
| You don’t have Blackwell hardware (no B200/B100) | Do not use FA4 | There is no benefit to attempting FA4: it is tailored to SM10.0 and won’t compile/run correctly on SM8.x/9.x. Pick the newest FlashAttention version supported by your GPU instead (FA2 for Ampere/Ada, FA3 for Hopper). |
| You have Blackwell (B200/B100) and your workload is inference-only | Test FA4 (forward) first, with a fallback | FA4 is forward-first today, so inference is the best match. Expect the largest benefit on long sequences and standard attention patterns. Keep cuDNN/SDPA fallback enabled to avoid hard failures or regressions if a feature is missing. |
| You have Blackwell and your workload is training (needs backward) | Prefer a mature training path until FA4 backward exists | Training requires a backward pass. With FA4 forward-only, your backward likely falls back to another kernel, which can dominate step time. Options: (a) train on Hopper with FA3 if available, (b) accept slower backward on Blackwell for now, © wait for FA4 backward support. |
Your model needs variable batching (ragged batches via cu_seqlens) |
Avoid FA4 unless you can pad or accept a fallback | If FA4 lacks varlen support in your stack, you’ll see errors or silent fallbacks. Workarounds: pad to uniform lengths, bucket by length, or disable FA4 for varlen cases. |
| Your model uses GQA/MQA (grouped-query heads, Llama variants, etc.) | Validate carefully; be ready to disable FA4 | If GQA is not supported in FA4 for your path (especially backward, and sometimes forward), you may get incorrect behavior or fall back. Use a known-good backend (FA3/cuDNN/SDPA) until GQA is confirmed in your environment. |
| You want FP4 or ultra-low precision features | Do not assume FA4 enables this yet | FA4 adoption should start with BF16/FP16. FP4 usage depends on kernel + framework support and is not something to plan on for early FA4 deployments unless explicitly documented in your toolchain. |
| You need maximum stability and “battle-tested” behavior | Choose the most mature option for your GPU (often FA3 on Hopper, FA2 on Ampere, cuDNN/SDPA fallback on Blackwell) | FA4 is new and evolving; early releases can have missing features and edge-case bugs. If production risk is unacceptable, prioritize mature kernels and only introduce FA4 behind a feature flag with strict correctness checks. |
| You can experiment and optimize aggressively | Adopt FA4 incrementally on Blackwell | Best approach: enable FA4 for a narrow slice (inference, long-seq buckets, non-GQA, fixed-length), measure throughput/latency, verify numerics, then expand coverage as support improves. |
FAQs
What problem is FlashAttention 4 (FA4) trying to solve?
It reduces attention’s heavy HBM memory traffic by computing attention tile-by-tile on-chip, avoiding materializing the full QK⊤ matrix.
What is the headline architectural change in FA4 vs FA3?
FA4 uses a warp-specialized, ~5-stage pipeline (load, compute, softmax/normalize, rescale/reduce, store) to increase overlap and on-chip reuse on Blackwell (SM10.x).
Why does FA4 compute exponentials on CUDA cores instead of SFUs?
Since SFUs are scarce and can easily become a bottleneck when computing softmax, FA4 spills over to computing a software approximation of exp2() on CUDA cores instead.
What does “adaptive online rescaling” change in softmax?
Rather than rescaling whenever a new max appears, FA4 only rescales when that max increases by a significant amount. This reduces rescale overhead while maintaining numerical stability.
When should an engineer adopt FA4 in production today?
Start with Blackwell inference-only, fixed-length, standard attention behind a feature flag; keep cuDNN/SDPA (and FA3/FA2 on older GPUs) as fallbacks until backward/varlen/GQA support is mature.
Conclusion
FlashAttention 4 builds on FlashAttention’s goal of reducing the memory-bandwidth demands of attention by doing more of the Q/K/V work on-chip. However, unlike prior versions, FA4 does this with a Blackwell-specific warp-specialized 5-stage pipeline and two major softmax improvements (using software exponentials on CUDA cores to alleviate SFU bottlenecks; and using adaptive online rescaling to eliminate redundant stability calculations). FA4 has shown respectable forward-pass throughput improvements over cuDNN at long sequence lengths, but remains forward-first and Blackwell-only. Furthermore, FA4 today has significant feature gaps (missing backward, varlen, GQA, etc.), and ecosystem support is not fully baked. The takeaway for now is to consider FA4 paths for Blackwell inference as a potentially high-upside avenue that requires adoption behind rigorous benchmarking, correctness, and fallbacks. At the same time, training workloads and broader hardware should continue to use the mature FA3/FA2 code paths for production.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
