AI/ML Technical Content Strategist

The model didn’t regress. You didn’t ship a bug. The platform changed it.
Your production AI applications depend on something most teams don’t realize they’ve handed over control of: the behavior of the model behind their endpoint. The reality is that a model is not a fixed artifact. It is a moving target. To stay competitive, platforms continuously update weights, swap quantization levels, upgrade inference engines, reroute traffic across hardware, and sometimes replace the model entirely - without changing the endpoint name.
When that happens, your application changes with it. Outputs shift. Prompts stop working. Carefully tuned behavior degrades. And you usually don’t find out from a changelog: you find out from a user.
This is the hidden risk of modern AI infrastructure: you are building on top of a system that can change underneath you at any time, with no guarantee that “the same model” tomorrow is the same model you tested today. This article explores what that looks like in practice, why it happens, and why almost no platform has solved it well - and what teams are doing to cope with it.
The model you shipped with is not the model you’re running.
Key Takeaways
- “Model versioning” is incomplete by design: What looks like a single model is actually a stack of moving parts - weights, inference engines, hardware, routing, and guardrails - all of which can change independently without the endpoint name changing.
- Silent changes create real production risk: These updates break reproducibility, invalidate prompt tuning, and introduce regressions that teams often detect only after users are impacted - not through platform visibility or monitoring.
- The gap is not technical - it’s transparency and ownership: Platforms already track these changes internally but don’t expose them; as AI becomes production-critical, full-stack versioning, changelogs, and reproducibility guarantees will become key criteria in platform selection.
The Shape of the Versioning Problem
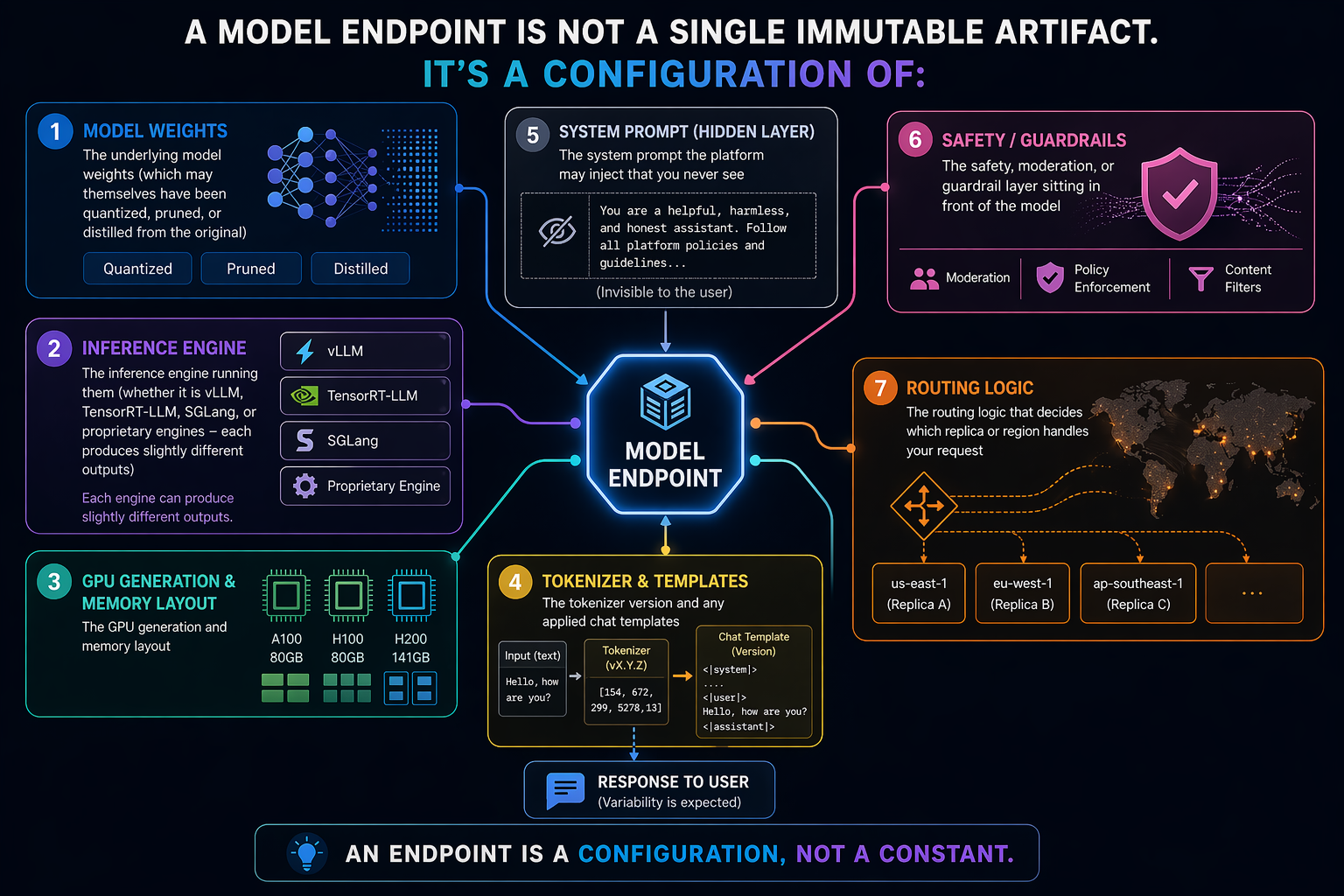
What “the same model” actually means
A model endpoint is not a single immutable artifact. It’s a configuration of:
- The underlying model weights (which may themselves have been quantized, pruned, or distilled from the original)
- The inference engine running them (whether it is vLLM, TensorRT-LLM, SGLang, or proprietary engines - each produces slightly different outputs)
- The GPU generation and memory layout
- The tokenizer version and any applied chat templates
- The system prompt the platform may inject that you never see
- The safety, moderation, or guardrail layer sitting in front of the model
- The routing logic that decides which replica or region handles your request
Any of these can change without the model name changing. What is critical to hit home with is that most of them do change, regularly, across the lifetime of a production application. This change is essential to the development of AI products as the underlying technology, usually, improves with each change. This incremental change is a core part of the AI Software industry.
The three categories of silent change
The first category is explicit version updates where the platform changes which weights the endpoint points at. “GPT-4” has been multiple different models over time, for example, and Claude endpoints get updated regularly. Open-source model endpoints on hosted platforms often track upstream releases automatically.
The second category is infrastructure-level changes where the weights stay the same but something in the serving stack shifts. Some examples of this include when:
- Inference engines get upgraded
- Quantization levels change for cost reasons
- Routing decisions shift traffic between different deployments that were supposed to be equivalent but aren’t.
The third category is behavioral changes from platform-level additions: new moderation layers, changed system prompts, added safety filters, or modified chat templates. In these scenarios, the model is the same, but what the model receives and what the user receives are different.
How Each Category Actually Affects Model Behavior
The silent regression problem
Silent regression is the degradation of model output quality caused by a change somewhere in the serving stack that was never announced, never documented, and never tied to a version bump. The model name on the endpoint is the same. The API contract is the same. The request you send is byte-identical to the one you sent last month. But the response quality has dropped - sometimes subtly, sometimes sharply - and nothing in the platform’s public surface tells you why.
The mechanism is almost always one of the three change categories from earlier: weights were quietly updated, something in the infrastructure shifted, or a platform-level layer (a new guardrail, a revised system prompt, a tightened moderation filter) was added or changed. From the outside, all three look identical - your outputs got worse and the platform didn’t tell you. From the inside, they’re different root causes with different fixes, and you have no way to distinguish them without the platform’s cooperation.
What makes silent regression distinct from ordinary model drift is the asymmetry of information. The platform knows what changed. You don’t. And because your monitoring is almost certainly measuring uptime, latency, and error rates rather than output quality on a golden dataset, the regression propagates to your users before it shows up on any dashboard you own. By the time you’ve confirmed the regression is real, isolated it to the model rather than your own code, and opened a support ticket, the platform has typically already moved on to the next silent change. You end up debugging a moving target with half the information, while your users absorb the cost of a decision made somewhere upstream that you were never told about.
This is the worst of the four problems in this section because it’s the only one where the platform holds information that would resolve the issue instantly and chooses not to share it. Reproducibility failures, prompt debt, and eval-to-prod drift are all symptoms teams can at least diagnose on their own. Silent regression is the one where the diagnostic tool you need is on the other side of the API.
The reproducibility problem
While GPT models, as an excellent example of a popular AI deployment type, are by nature probabilistic, you can still expect to get similar answers when using the same model with the same prompt. But, when any of the changes described earlier happen, an output you got yesterday may not be reproducible today. This is the crux of the reproducibility problem: any expectations of how a model will behave can be invalidated by any of these changes.
For applications doing automated evaluation or comparing model versions against each other, this breaks the fundamental assumption that identical inputs produce identical (or similar, in the case of probabilistic models) outputs given the same seed. Temperature zero doesn’t actually give you determinism when the underlying stack is shifting under you. The prompt engineering debt problem
Teams often spend weeks at a time tuning prompts for a specific model’s quirks and optimizing them to better meet their users’ needs. When that model is silently swapped or updated, all that tuning work turns into partial debt. When prompts that were carefully constructed to handle one model’s failure modes now encounter a slightly different model with slightly different failure modes, the eventual behavior your users meet with changes.
The eval-to-production drift problem
Here’s another common scenario: you evaluate a model version against your test set, and subsequently ship it to production. But the production endpoint is no longer using the model you evaluated, even if the name on the endpoint is the same. Once again, this can have a notable effect on the behavior of the final product.
What the Platforms Actually Do
This section walks through how major inference platforms handle versioning, based on public documentation and observable behavior.
OpenAI-style versioning
OpenAI pins snapshots explicitly (gpt-4-0613, gpt-4o-2024-08-06) and lets you target them. The aliased endpoints (gpt-4, gpt-4o) point at whatever the current default is, which changes over time. Teams that don’t know to pin snapshots get whatever version is current, and the alias can shift under them.
OpenAI does change their models though, for various reasons. One example of this is the Sycophancy Incident. GPT-4o was reportedly ‘overly flattering or agreeable — often described as sycophantic,’ and OpenAI issued a series of rollout corrections before eventually deprecating the model (source). The eventual deprecation of the model made more waves as people lamented the loss of the model.
What makes the Sycophancy Incident instructive isn’t the personality shift itself - it’s what it revealed about the endpoint contract. Teams calling gpt-4o before, during, and after the sycophancy rollout were hitting the same endpoint name but meaningfully different models. A customer support bot tuned against the pre-sycophancy version would have encountered a warmer, more agreeable model partway through its production lifetime, then encountered a third behavior profile when OpenAI corrected course, and a fourth when the model was eventually deprecated. None of those transitions required a code change on the customer’s end. None of them triggered a version bump on the endpoint string. The same two-line API call produced four distinct behavioral regimes over the course of months, and the only signal most teams got was their users telling them the product felt different. OpenAI’s approach is better than most because it gives you the option of using older model versions, as long as OpenAI is still serving them. But, it is still worth noting that the selection is manual and will be difficult to do for those who don’t do the research to know how to change the model to the older versions.
Anthropic’s approach
Anthropic uses dated model identifiers (claude-opus-4-5-20251101 style). Pinning works. But the platform-level system prompt injection and safety layer evolve independently of the model version, so two requests to the same pinned model on different days can behave differently because of what’s happening around the model, not in it. This is a step away in transparency, but the core model selection remains similar to that of OpenAI.
An example of silent regression from Anthropic happened recently in a notable Github Issue, where a major AI developer called out the apparent “nerfing” of the Claude Opus models in their complex engineering work. They reported that Claude had begun ignoring instructions, claiming “simplest fixes” that are incorrect, doing the opposite of requested activities, and they claimed the model performed completion against instructions. All of this without a reported change in the model being used. This silent change was refuted by Claude’s developers in the same thread, but there is wide agreement that a change did take place from other users, based on the responses to the comment.
‘The same model’ has always been a marketing abstraction.
Hosted open-source models
Platforms hosting open-source models (Baseten, Fireworks, Together, DigitalOcean, Nebius Token Factory, Modal) often name endpoints after the underlying model, such as “llama-3.1-70b-instruct”, without exposing which specific quantization, which inference engine version, or which deployment configuration is actually serving the request. This can be a big problem, as the performance of the model will vary from platform to platform while they hold the same name. Updates to any of those are not typically communicated as model version changes. When it comes to open-source hosting providers, the onus is on the user to do the research about any changes to the underlying model deployment in Serverless Inference scenarios. In custom deployments, things are a bit different.
Custom deployments
When you deploy your own model on a platform like Modal or Baseten, you own the versioning story. This is the cleanest situation for reproducibility, control over production, and managing model changes for your downstream products, but it means taking on the operational burden of managing the model lifecycle yourself. It’s critical to consider this tradeoff when scaling, as the developer time required to manage the changes skyrockets.
What Teams Are Doing About It
The sections below cover the common workarounds teams have adopted. None of them fully solve the problem, but they each offer steps in the right direction. Snapshot pinning when possible
When the platform exposes dated snapshots, pinning them is table stakes. But not every platform exposes them, and pinned snapshots get deprecated eventually. Consider this when selecting which platform for hosting your model for your AI products carefully, or you may end up in a situation where your model is gone without a back up plan.
Golden dataset regression testing
Golden dataset regression testing is where you run a fixed set of inputs through production endpoints on a schedule and diff the outputs against a known-good baseline. This process allows you to easily catch quality regressions and other significant model behavior changes, but it is expensive to maintain, and can only cover the patterns you thought to observe. Regular golden dataset regression testing can prevent the dreaded news that a customer has discovered your product’s behavior change before you did.
Output sampling and logging
This is the process of logging a sampled percentage of production requests and responses for later analysis. This lets you detect drift after the fact, but still requires building the sampling, storage, and analysis infrastructure yourself.
Shadow deployments
You can run the same request against the current production endpoint and a candidate new endpoint simultaneously, and compare the outputs to see how that affects model behavior. This works excellently for evaluating changes you’re making; it doesn’t help with changes the platform makes under you.
Self-hosting the model
The ultimate control move: run the model yourself on infrastructure you control. This allows you to have complete control over the weights you are using, the inference engine, the quantization, and anything else that may affect the output. This trades the versioning problem for the operational burden of model hosting, which is why most teams don’t do it.
The observability tax
Every team that cares about output quality is building their own evaluation infrastructure because the platforms don’t provide it. This is duplicated work happening across the industry - prompt regression frameworks, output diffing tools, quality monitoring systems, etc., all being built by application teams who’d rather be building their actual product. The trust tax
When your AI feature breaks because the model shifted under you, users don’t know the difference between “the AI is unreliable” and “the platform silently updated the model.” Your product absorbs the reputational cost of decisions made upstream.
The migration tax
Teams considering switching platforms have to account for not just API differences but behavioral differences between the same-named models on different platforms. “Llama 3.1 70B” on Fireworks is not necessarily the same as “Llama 3.1 70B” on Together - they may be a different quantization, use a different inference engine, or have a completely different guardrail stack. This lack of clarity makes it difficult to switch between providers without extensive testing.
What Better Would Look Like
A serious inference platform in 2026 should treat model behavior the way cloud providers treat uptime: as a contractual surface, not a black box.
The current state isn’t a technical limitation - it’s a disclosure gap. The infrastructure already exists to track weights, engines, quantization levels, and routing decisions; platforms simply don’t expose it.
Here’s what that looks like in practice.
-
Complete version identifiers Today’s model names identify the weights, sometimes. They should identify the full serving configuration. A complete version string captures everything that can change what comes out of the endpoint: weights (with quantization level), inference engine and version, hardware generation, tokenizer version, chat template, and any platform-injected system prompt or guardrail layer. Something like llama-3.1-70b-instruct.fp8.vllm-0.6.3.h100.tmpl-v2.guardrail-v4 is ugly but honest. Teams could pin any component they depend on and receive notifications when others change.
-
Changelog feeds for the whole stack Platforms publish release notes when they update model weights. They rarely publish anything when they upgrade vLLM, change quantization for cost reasons, or reroute traffic between regions. A proper changelog feed - ideally machine-readable - would cover every layer of the serving stack, with timestamps and affected endpoints. Teams should be able to subscribe to changes for a specific pinned configuration and receive alerts before rollout, not after a user complains.
-
Reproducibility guarantees with stated retention A pinned snapshot should mean something. Platforms should commit to a stated retention window - say, 12 or 24 months - during which a pinned configuration will return byte-identical outputs for identical inputs at temperature zero, for the full stack, not just the weights. When that window expires, teams get advance notice and a migration path. This is how databases and operating systems handle versioning. There’s no reason inference should be different.
-
Platform-provided regression testing Every serious team is building the same evaluation infrastructure in isolation. Platforms should provide this as a first-class feature: register a golden dataset, run it on a schedule against your pinned endpoint, and get alerted when outputs drift beyond a threshold you set. Bonus points for differential testing between snapshots, so teams can evaluate whether to migrate before they’re forced to.
-
Honest documentation about what changes and when The hardest item on this list, because it requires platforms to admit that “the same model” has always been a marketing abstraction. Documentation should name every layer that can change independently of the model version, state the platform’s policy on changing each one, and describe how customers will be notified. Teams can then make informed decisions about which platforms match their risk tolerance.
A buyer’s checklist
If you’re evaluating an inference platform today, ask the vendor these questions before signing:
- “Can I pin a specific model snapshot, and for how long is that snapshot guaranteed available?”
- “Does the version string I pin cover the inference engine, quantization, and hardware - or only the weights?”
- “What is your notification policy when any layer of the serving stack changes?”
- “Do you inject system prompts, guardrails, or moderation layers I can’t see? Can I opt out?”
- “If I run the same request twice at temperature zero a month apart, what guarantees do you make about output identity?”
- “Do you provide regression testing tooling, or do I build it myself?”
- “When a pinned snapshot is deprecated, how much notice do I get and what’s the migration path?”
If a platform can’t answer most of these clearly, that’s the answer. You’re building on infrastructure that can change underneath you, and you’ll be the one explaining it to your users.
The Commercial Reality
None of the above is technically hard. What makes it hard is commercial: platforms benefit from the flexibility to change things quietly, and customers have historically accepted it because the alternative, self-hosting, is operationally expensive. That trade is starting to look worse as AI features move from demos into products people depend on. The platforms that solve this first will win the segment of the market that actually cares about reliability. The ones that don’t will keep shipping silent regressions to teams who find out from their users.
Closing Thoughts
The industry built AI infrastructure on an assumption borrowed from traditional software: that a named artifact is a stable artifact. That assumption doesn’t hold. Weights, engines, routing, and guardrails all change independently of the name on the endpoint, and the gap between what “model version” implies and what it actually guarantees is where production AI quietly breaks.
Here’s the prediction: within the next 18 months, silent versioning will become a procurement issue, not just an engineering one. The teams buying inference capacity are starting to ask the questions in the checklist above, and the platforms that can answer them will start winning deals the others don’t even know they’ve lost. Expect to see “reproducibility SLAs,” “stack-level changelogs,” and “snapshot retention windows” move from engineering wishlists into enterprise contracts. The first platform to publish a full-stack version string as a product feature - not a deep-in-the-docs footnote - will reset customer expectations for everyone else.
For teams building on top of inference today, the practical question isn’t whether silent change will affect your product. It will. The question is whether you find out from your monitoring, from your own regression tests, or from a user complaint on a Monday morning. Which of those three it is depends almost entirely on decisions you make now, before the next silent update lands.
The model you shipped with is not the model you’re running. Build accordingly.
DigitalOcean can help you build your AI products at scale.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
