Mastering the 600B+ Frontier: Optimizing Large Model Deployments on the Inference Cloud
By Brett Snyder
Principal Engineer
- Published:
- 9 min read
We have moved past the point where a 70GB model was considered “heavy.” With the rise of models like DeepSeek-V3, the GLM series, and other massive Mixture-of-Experts (MoE) architectures, the industry is now grappling with weights exceeding 700GB in optimized formats—and well over 1.2TB in full precision. And parameters keep climbing—Epoch’s AI data tracks frontier models now reaching into the trillions of parameters, with no sign of plateau.
At this scale, “Data Gravity” isn’t just a metaphor; it is a structural bottleneck. If your storage architecture isn’t optimized for these massive assets, the latency of moving weights into VRAM can undermine the unit economics of your entire GPU fleet. Every time an agent orchestrating a multi-step workflow hands off to a different specialized model, the user on the other end is waiting—and what they’re waiting on is your storage layer, not your intelligence.
Deploying production workloads to an inference cloud that provides both GPUs and storage optimized for GPU consumption will often be non-negotiable as model sizes continue to grow.
The Cost of the “Idle Wait”
When deploying GPU infrastructure, the most expensive resource can be idle silicon. A standard 1Gbps connection is fundamentally incapable of supporting modern large-scale models, requiring hours to “pull” a single checkpoint. Even at 10Gbps, the “Data Tax”—the time spent waiting for weights to load—can lead to 15-20 minute cold starts.
In agentic workflows, where a primary agent may need to spin up specialized “expert” nodes on demand, these delays can create a cascading failure. If your infrastructure can’t scale a node and load its model in under two minutes, real-time agentic behavior becomes impossible. This might look like a coding agent calling a specialized security-auditing model mid-task, where a five-minute cold start means the user has already abandoned the session.
The ROI of High-Bandwidth Storage
To understand why high-throughput storage matters, we have to look at the unit economics of a production GPU cluster. An 8-GPU cluster of NVIDIA HGX H200s costs $27.52 per hour ($3.44 per GPU/hr).
In a “Cold Pull” scenario—where 700GB+ of model weights are being moved over a standard 10Gbps link—your cluster can sit idle for up to 10 minutes during a deployment or scaling event.
The “Data Tax” Breakdown (8-GPU Cluster), 720GB model
At $27.52/hr, every minute of idle time costs roughly $0.46. While that sounds small, the cumulative cost of deployment latency for an elastic agentic workflow can be significant:
| Metric | Standard Pipe (10Gbps) | 32 TiB High Performance NFS (40Gbps) | Spaces Object Store (22Gbps) |
|---|---|---|---|
| Model Transfer Time (720GB) | ~9-10 minutes | ~2-3 minutes | ~4-5 minutes |
| Idle Silicon Cost (Per Event) | ~$4.13-$4.59 | ~$0.92-1.38 | ~$1.83-$2.29 |
| Savings per Deployment | $0 | ~$3.21 | ~$2.30 |
| Savings % Over Standard Pipe | 0% | 70-77% | 50-55% |
Why This Matters for CTOs
Under the scenario above, if your agentic system scales up and down 10 times a day to handle traffic bursts, a slow storage tier wastes nearly $41-$46 per day per cluster on literally nothing. Over a month, that’s $1239-$1377 in burned capital per cluster just for the “privilege” of waiting for data to move.
The math flips once storage stops being the bottleneck. When model weights load in under three minutes instead of ten, the burned capital becomes compute you’re actually using. By using a High Performance Managed NFS share, you aren’t just improving developer experience; you are potentially reclaiming up to 77% of your deployment-related overhead.
Optimized Model Storage
Object storage and NFS are two popular options for storing models. They both come with unique strengths in the inference ecosystem. Object storage is a great fit for storing your immutable “gold master” models. NFS, on the other hand, is excellent for AI/ML training, shared datasets, and partial file writes.
As model sizes continue to grow, both types of storage need to support higher throughput access to reduce cold starts and keep GPUs saturated during inference.
To solve these Data Gravity problems, we have engineered our Spaces Object Storage and Managed NFS products to provide multiple high-bandwidth pathways for model weights.
Spaces Object Storage: Optimized to 22Gbps
For many developers, Spaces Object Storage is the primary entry point for model ingestion. We have optimized throughput on Spaces to achieve up to 22Gbps against a single bucket (across parallel requests). This allows for fast retrieval of your models across many parallel consumers using s3:GetObject calls.
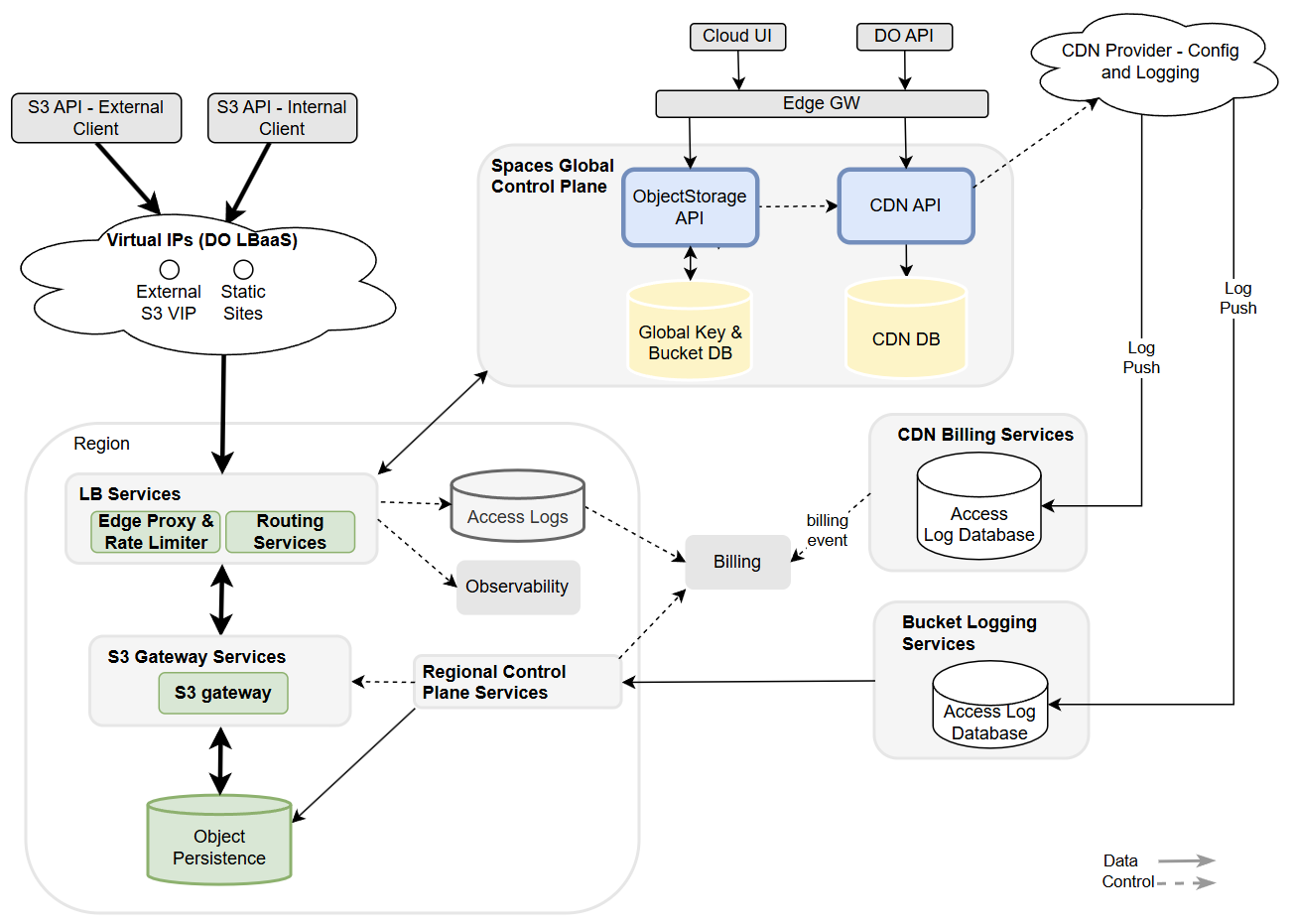
Speed is only half the battle during agentic inference. Reliability at the TB-scale is the other. Standard object storage pulls often suffer from “Connection Reset” and “Timeout” errors when handling single streams of massive data.
The move to a POSIX-compliant file system like NFS reduces these failures because the file system handles the consistency and state of the transfer and engineers encounter fewer “ImagePullBackOff” or “Corrupted Shard” errors during critical scaling events.
High Performance Managed NFS: The 40Gbps Warm Tier
For production environments where every second of deployment latency counts, our High Performance Managed NFS tier delivers up to 40Gbps. By treating your model weights as a “warm” mountable asset rather than a “cold” download, you fundamentally change the deployment math:
-
POSIX Compliance and Efficiency: POSIX means that the storage behaves like a local hard drive. For AI workloads, most modern ML frameworks use mmap to map model weights directly into virtual memory. The OS can demand specific bytes needed for a calculation instead of downloading the entire file to RAM.
-
Mount-on-Boot: Instead of downloading 700GB+ to a local disk, nodes mount the shared NFS volume. This allows the model to be immediately available to the application layer and across multiple nodes at once.
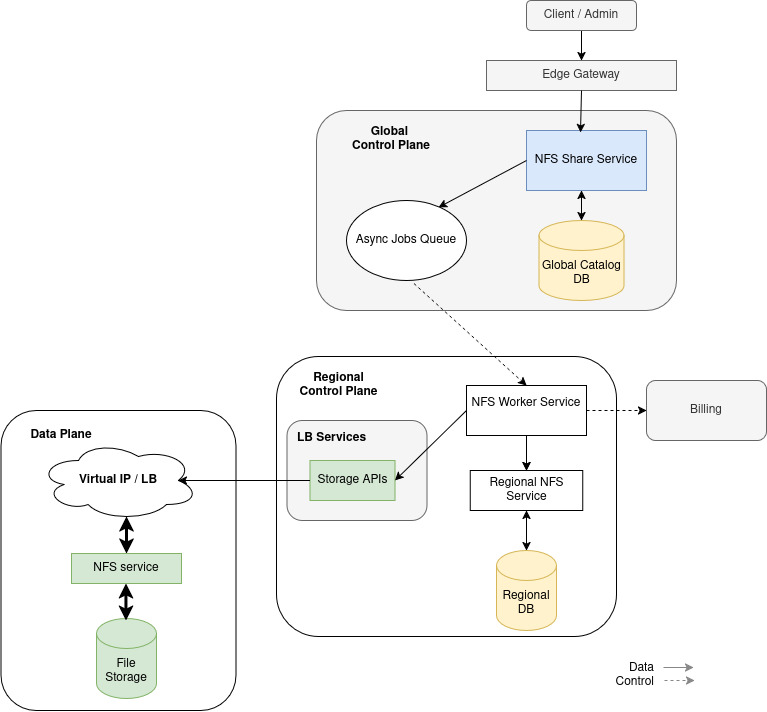
Tuning DigitalOcean Managed NFS for High Throughput
When we architected our managed NFS offering, we had to solve for the “noisy neighbor” problem while ensuring that performance wasn’t just a static ceiling, but a dynamic resource that grows with your footprint. From a systems perspective, we treat storage capacity as the primary lever for performance. We offer both a Standard performance tier and a High performance tier. As you scale the size of your High performance tier share, we increase the throughput limits. This isn’t just about disk speed; it’s about the underlying network throughput and the CPU cycles allocated to the filesystem daemon.
| Performance Tier | Share Size | Read Throughput | Max Read IOPs |
|---|---|---|---|
| STANDARD | Any Size | 1 Gbps (flat) | 10,000 |
| HIGH | <= 1 TiB | 8 Gbps | 100,000 |
| HIGH | 1-2 TiB | 9 Gbps | 100,000 |
| HIGH | 2-3 TiB | 10 Gbps | 100,000 |
| HIGH | 16 TiB | 24 Gbps | 100,000 |
| HIGH | 32 TiB | 40 Gbps | 100,000 |
Hitting 40 Gbps is less about pipe size and more about how many lanes you can use simultaneously. Using default client side mounting options will not allow you to achieve maximum throughput. Here are the settings we recommend tweaking to help ensure you get the most performance out of your share.
1. Parallelizing the Path with nconnect
By default, NFS operates over a single TCP connection. Even with a 100GbE interface, a single connection often caps out due to single-core CPU limitations or protocol overhead. We use the nconnect mount option to distribute traffic across multiple parallel TCP connections.
# Example mount configuration for high-throughput concurrency
mount -t nfs -o rw,nconnect=16,rsize=1048576,wsize=1048576 <STORAGE_IP>:/ /mnt/models
2. Reducing CPU Overhead with Jumbo Frames
Standard Ethernet frames are 1500 bytes. Moving 1.5TiB of data in 1500-byte increments creates massive interrupt overhead for the CPU. By implementing Jumbo Frames (MTU 9000), we pack more data into every packet. This helps reduce the number of headers the kernel has to process, freeing up CPU cycles for the actual inference engine.
ip link set eth1 mtu 9000
3. Expanding the TCP Window
To sustain 40 Gbps, the kernel needs a massive “memory buffer” to handle data in flight. We tuned the rmem and wmem values to 128MB to ensure the TCP window never shrinks, preventing throughput “saw-toothing.”
# Sysctl tuning for high-bandwidth model streaming
sysctl -w net.core.rmem_max=134217728
sysctl -w net.core.wmem_max=134217728
sysctl -w net.ipv4.tcp_rmem='4096 87380 134217728'
sysctl -w net.ipv4.tcp_wmem='4096 65536 134217728'
4. Handling the Backlog
High-speed data is useless if it overwhelms the operating system. When streaming at 40 Gbps, the kernel’s input queue can fill up instantly, leading to dropped packets and failed inference jobs.
We increased the netdev_max_backlog to 500,000. This allows the system to help buffer a massive influx of packets from the network interface before they are processed by the stack.
sysctl -w net.core.netdev_max_backlog=500000"
Hitting the Wall
The KV Cache holds the mathematical representations of every token the model has already processed. This cache grows linearly with sequence length. With large token windows, the cache can easily occupy dozens to hundreds of gigabytes—sometimes more than the model weights themselves.
If the size of this KV Cache grows larger than the GPUs HBM (High Bandwidth Memory), the system typically crashes or swaps to system RAM over a much slower PCIe bus. This creates a performance cliff where you go from processing hundreds of tokens per second to effectively zero.
When the GPU has to reach across the PCIe bus to fetch data from system RAM it introduces latency. In the time it takes the GPU to fetch one chunk of the KV cache from RAM, it could have performed thousands of calculations. The “engine” is essentially idling, waiting for fuel. A well-optimized model might hit 50-100 tokens per second (TPS), but once it swaps to RAM over PCIe, it often drops to 0.5-1 TPS.
| Component | Throughput |
|---|---|
| GPU HBM | ~ 2,000-3,300 GB/s |
| PCIe Gen5 | ~ 64 GB/s |
| Local System RAM | ~ 50-100 GB/s |
Using System RAM over PCIe has other downsides besides being many times slower than HBM. System RAM is a local silo and is volatile memory. If your inference service restarts or scales down, that portion of the KV Cache is gone and will require paying the “Prefill Tax” to re-calculate it.
For large models, you are almost certainly running multiple GPUs. If the KV Cache is stuck in the System RAM of Node 1, but Node 2 needs it to continue a decoding task, Node 1 needs to send that data over the network to Node 2 anyhow. If instead the KV Cache is stored in persistent storage, there will be no need to re-pay the “Prefill Tax” on scale up / down events.
Projects like LMCache already support storing KV Cache to disk as well as S3-compatible storage for both long context LLM use cases as well as multi-round QA and RAG.
KV Cache as Virtual VRAM for 600B+
For a 600B parameter model, the weights take up roughly 300-350GB. At this parameter count, the “width” of the model is massive. A 128k token context window for a 600B model can generate a KV cache exceeding 500GB. The total memory requirement of weights plus context window is 800-850GB. Even an 8-node H100 cluster (640 GB total VRAM) will hit the “out of memory” wall.
With models of this size (and the ever-larger ones being developed), you are no longer just offloading overflow; you are architecting a system where the majority of your “active” data lives on the storage fabric by necessity.
When models are this large, the KV cache becomes the most volatile and memory-intensive part of the workload. In smaller models, offloading is a luxury. In 600B+ models, layer-wise KV offloading is the future. A large model system can:
-
Compute Layer 1
-
Push Layer 1’s KV Cache to Storage
-
Clear HBM for Layer 2
-
Pull Layer 1 back when the next token starts
Persistent KV Cache offloading helps bridge the gap between hardware limits and frontier-scale intelligence. By moving the cache to high-performance shared storage, you help enable massive context windows and near-instant prefill recovery that standard HBM and System RAM simply cannot accommodate. In Prefill-decode (PD) disaggregation architectures, this allows the prefill nodes to hand off processed context to decode nodes without traditional network bottlenecks. With the KV state persisted, you eliminate redundant computations and enable global access to the KV cache across a multinode cluster, helping to ensure that even 600B+ parameter models can resume long-context sessions instantly.
Next Steps for Managed NFS
We are actively working on expanding our Managed NFS offering with Remote Direct Memory Access (RDMA) and GPUDirect capability. These additions should allow us to push the throughput envelope even further and allow KV Cache offloading for your most critical workloads.
Architecting for the Next Generation
In the era of 1.5TiB models, storage throughput can be the ultimate inference model differentiator. By optimizing the kernel, storage, and network fabric, we help ensure your GPUs spend their time computing, not waiting. When your cloud provider handles both the compute and the storage, you skip the integration headaches of stitching them together yourself.
Spaces Object Storage serves as the archive where your “gold master” 600B+ models live. High Performance Managed NFS acts as your high-throughput "holding area,” where models are mounted across dozens of GPU Droplets simultaneously.
As even larger models emerge, the strategy is clear: keep your models hot. Pairing these two storage layers helps to ensure your infrastructure is ready for whatever comes next.
About the author
Related Articles

The LLM Inference Trilemma: Throughput, Latency, Cost
- April 22, 2026
- 12 min read

The Inference Cloud Memory Layer: A Technical Dive into DigitalOcean Managed Databases
- April 17, 2026
- 10 min read

Load Balancing and Scaling LLM Serving
- April 15, 2026
- 7 min read